Combinando Sigmoid y entropía cruzada binaria de forma estable
BCEWithLogitsLoss es una función de pérdida ampliamente utilizada en clasificación binaria y multilabel que combina:
- una activación Sigmoid
- entropía cruzada binaria
👉 todo en una implementación numéricamente estable.
Definición corta
BCEWithLogitsLoss calcula la pérdida de clasificación binaria directamente sobre logits sin aplicar Sigmoid manualmente.
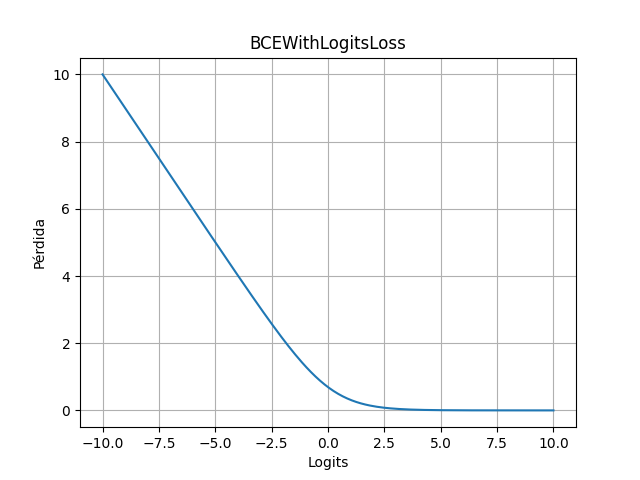
🧠 Intuición
Esta función responde:
👉 “¿Qué tan incorrectas son las probabilidades implícitas en los logits del modelo?”
Logits ↓ Sigmoid interna ↓ Probabilidades ↓ Binary cross-entropy
🔹 ¿Qué son los logits?
Los logits son valores sin normalizar producidos por el modelo:
[-2.1, 0.5, 3.2]
👉 aún no son probabilidades.
📐 Función Sigmoid interna
👉 convierte logits en probabilidades.
📐 Binary Cross-Entropy
👉 penaliza predicciones incorrectas.
🧠 ¿Por qué usar BCEWithLogitsLoss?
Porque es:
- más estable numéricamente
- más eficiente
- menos propensa a overflow
📊 Ejemplo conceptual
Sigmoid manual + BCE ↓ Posibles errores numéricos
BCEWithLogitsLoss ↓ Implementación optimizada
🔄 Diferencia con BCELoss
| Función | Entrada esperada |
|---|---|
| BCELoss | probabilidades |
| BCEWithLogitsLoss | logits |
👉 diferencia extremadamente importante.
⚠️ Error muy común
❌ Aplicar Sigmoid antes de BCEWithLogitsLoss.
Logits ↓ Sigmoid manual ↓ BCEWithLogitsLoss ↓ Problemas
👉 la función ya incluye Sigmoid internamente.
🧠 Uso típico
Se utiliza en:
- clasificación binaria
- clasificación multilabel
- detección de anomalías
- sistemas probabilísticos
📊 Ejemplo conceptual
Modelo ↓ Logits ↓ BCEWithLogitsLoss ↓ Optimización
🧠 Relación con multilabel
En multilabel:
- cada clase usa Sigmoid independiente
- BCE se aplica por clase
📊 Ejemplo conceptual
Clase A → probabilidad Clase B → probabilidad Clase C → probabilidad
👉 las clases no compiten entre sí.
🧠 Estabilidad numérica
Internamente usa transformaciones matemáticas más seguras para evitar:
- overflow
- underflow
- NaNs
📊 Ejemplo conceptual
Logits extremos ↓ Cálculo estable
📊 Ejemplo en PyTorch
import torchimport torch.nn as nnloss_fn = nn.BCEWithLogitsLoss()logits = torch.tensor([0.8, -1.2, 2.0])targets = torch.tensor([1.0, 0.0, 1.0])loss = loss_fn(logits, targets)print(loss)
Ejemplo incorrecto
❌ NO hacer esto:
sigmoid = torch.sigmoid(logits)loss = loss_fn(sigmoid, targets)
👉 porque la función ya aplica Sigmoid.
🧠 Qué muestran estos ejemplos
- trabajo directo con logits
- estabilidad numérica
- clasificación probabilística
🧠 Relación con Softmax
| Problema | Función típica |
|---|---|
| Binario / multilabel | BCEWithLogitsLoss |
| Multiclase | CrossEntropyLoss |
📊 Ejemplo conceptual
Multiclase → Softmax Multilabel → Sigmoid independiente
⚠️ Errores comunes
Aplicar Sigmoid manualmente
Muy frecuente.
Confundir multilabel con multiclase
Usan pérdidas diferentes.
Usar targets enteros incorrectos
Deben ser flotantes.
📊 Ejemplo conceptual en ML
Logits ↓ Sigmoid implícita ↓ Pérdida ↓ Backpropagation
🧠 Interpretación profunda
BCEWithLogitsLoss refleja un principio clave:
👉 Las probabilidades deben entrenarse de forma estable y matemáticamente consistente
Es una pieza esencial de:
- clasificación binaria moderna
- multilabel learning
- redes neuronales probabilísticas
👉 porque la función ya aplica Sigmoid.
🧠 Qué muestran estos ejemplos
- trabajo directo con logits
- estabilidad numérica
- clasificación probabilística
🧠 Relación con Softmax
| Problema | Función típica |
|---|---|
| Binario / multilabel | BCEWithLogitsLoss |
| Multiclase | CrossEntropyLoss |
📊 Ejemplo conceptual
Multiclase → Softmax Multilabel → Sigmoid independiente
⚠️ Errores comunes
Aplicar Sigmoid manualmente
Muy frecuente.
Confundir multilabel con multiclase
Usan pérdidas diferentes.
Usar targets enteros incorrectos
Deben ser flotantes.
📊 Ejemplo conceptual en ML
Logits ↓ Sigmoid implícita ↓ Pérdida ↓ Backpropagation
🧠 Interpretación profunda
BCEWithLogitsLoss refleja un principio clave:
👉 Las probabilidades deben entrenarse de forma estable y matemáticamente consistente
Es una pieza esencial de:
- clasificación binaria moderna
- multilabel learning
- redes neuronales probabilísticas
Ejemplo en Python
Este concepto incluye un ejemplo práctico en Python para ayudarte a entenderlo mejor:
